Reflections on a Transdisciplinary Study on XAI and Trust
Does explainability change how users interact with an artificially intelligent agent?
We sought to answer this question in a transdisciplinary research project with a team of computer scientists and
psychologists.
We chose the high-risk decision making task of AI-assisted mushroom hunting to study the effects that explanations
of AI predictions have on user trust.
We present an overview of three studies, one of which was carried out in an unusual environment as part
of a science and art festival.
Our results show that visual explanations can lead to more adequate trust in AI systems and thereby to an improved
decision correctness.
Citation information
This article contains results from previously published work and from unpublished preprints.
Cards like this one will guide you to the original sources for each section.
The potential dangers of artificial intelligence (AI) have been the subject of scientific, philosophical, and
artistic debates for many decades, even centuries.
Samuel Butler's 1872 novel Erewhon describes a utopian society that—out of fear of an AI
uprising—has
deliberately chosen to be absent of machines.
The Erewhonian Book of the Machines justifies this decision:
Assume for the sake of argument that conscious beings have existed for some twenty million years: see what
strides
machines have made in the last thousand!
May not the world last twenty million years longer?
If so, what will they not in the end become?
Is it not safer to nip the mischief in the bud and to forbid them further progress?
The book then continues with a statement that remarkably anticipates the sentiments of many people in 2023 :
I would repeat that I fear none of the existing machines; what I fear is the extraordinary rapidity with which
they are becoming something very different to what they are at present.
No class of beings have in any time past made so rapid a movement forward.
Indeed, recent leaps in the quality of generative models like DALL·E 2, Midjourney, or GPT-4 have resparked
intense concerns about the powers and dangers of AI.
But even more traditional classification and regression models can poses great risks, especially when applied in
high-stake scenarios or sensitive contexts.
Examples of such potentially problematic application areas are recidivism prediction , gender classification
, and road sign classification for autonomous driving. .
Discussions about the risks of AI, especially outside of academic circles, are seldom factual, and in these
discussions, AI systems are often talked up as autonomous agents with their own consciousness.
However, as Timnit Gebru and others have recently stated:
the harms from so-called AI [...] follow from
the acts of people.
This statement is true for both the processes of creating and using AI-powered systems.
In our transdisciplinary research project, we were particularly interested in the latter: how do people interpret,
use, and trust results from an AI system?
And what effects can explanations have on this behavior?
Trust Issues
Modern machine learning (ML) models can be highly complex and are often opaque.
Even ML experts may find it hard to understand how and why exactly a model arrives at a certain output.
This challenge has been met with attempts to find ways of explaining at least certain aspects of a model and/or
its output, or of making models themselves more interpretable.
A plethora of explainable AI (XAI) techniques have resulted from these attempts .
However, many of these techniques were developed by and for ML domain experts, and it is still poorly understood
how those techniques actually affect user behavior, in particular that of lay users.
Specifically, we were interested in how (visual) explanations for AI predictions affect the trust of
human lay users in these predictions.
We, by the way, are a team of psychologists interested in human–computer interaction and computer scientists
interested in visualization and XAI (and we also worked together with many more
people, without whom this project would not have been possible).
Users of real-world AI systems, who are confronted with an AI's prediction, face the problem of deciding whether
they want to go along with the AI (i.e., trust it), or overrule it and follow their own knowledge or gut feeling.
Obviously, AI systems are not infallible. It cannot be a goal to make users always trust an AI's
prediction—especially in delicate situations, overtrusting an AI can be dangerous.
Vice versa, undertrusting an AI can lead to poor decisions for tasks at which the AI actually performs
well (and there are more and more applications where AI can achieve superhuman performance ).
As a consequence, the main goal of XAI in relation to trust must be trust calibration, which means
bringing about an adequate level of user trust.
Enabling proper trust calibration for future applications requires an improved understanding of the effects
of existing techniques on user trust.
“Existing techniques”, in the context of this article, means mostly visual techniques for
explaining individual predictions of an AI. Throughout the last years, the visualization community has intensified
its work on the interplay of visualization, trust, and AI. The focus seems to have shifted from merely enhancing or
building trust , to better understanding and
calibrating trust .
Our work falls into the latter category.
Psychological research has established that trust can only be studied in contexts where people have a certain
degree of vulnerability and uncertainty .
For our research project, we were thus looking for a real-world use case that would fulfill the following
criteria:
Something had to be at stake.
Simple classification of cats and dogs on images wouldn't cut it.
It had to be relatable.
We wanted to conduct quantitative user studies, recruiting a broad and diverse range of
participants. Expert domains, such as medical image analysis, were out of the question.
We wanted it to be visual.
As researchers interested in visualizations, and with most XAI techniques being of
visual nature, we wanted the use case to be tied to images.
A Case for Mushrooms
Mushrooms are not only delicious, but it's also fun to collect them!
Soon after mushroom hunting was brought up in our discussions about potential application scenarios, we realized
that it perfectly fits the criteria outlined above.
Something is at stake.
While it's fun to collect mushrooms, there's quite a bit of danger associated with it.
Many edible mushrooms have inedible or poisonous doppelgangers.
Sometimes, only minute differences in appearance tell a seasoned mushroom collector which species they've
encountered.
And the species can make the difference between delicious food and deadly poison.
Take a look at the two images below.
One of the mushrooms pictured is a delicious parasol mushroom (macrolepiota procera).
It tastes great when breaded and fried like a cutlet.
The other one is a death cap (amanita phalloides).
Eating around 30 grams of it will kill you.
Can you spot the important differences?
One of these mushrooms is a delicious parasol, the other one a poisonous death cap. Can you spot the
differences?
Since ML models have become quite good at detecting certain features in images, AI-assisted mushroom hunting is
now a thing.
Several apps have already been released to the public, which let people take photos of mushrooms and then use an
AI to predict a species.
Due to the high risk posed by potentially deadly mushrooms, adequate trust in such systems is invaluable.
It's relatable.
Even though most experimental studies have a certain degree of artificiality about them (often because of ethical
considerations, but also to keep things under tight control), it's important that study participants can relate to
the task at hand.
While the popularity of mushroom hunting varies around the world, in Austria and Germany, where we are from, it is
quite a popular activity.
Many people here have been out in the forest collecting mushrooms themselves or at least know somebody who
regularly does so .
The same is true for most of central and northern Europe .
We were sure that there would be a fairly large target population for our study if we chose mushroom hunting as
the use case.
It's visual.
There are many different cues for deciding whether a mushroom belongs to a certain species.
While non-visual cues---such as smell, taste, and consistency---are certainly necessary for a reliable
classification, apps can only work with the visual cues.
These include relative sizes, colors, and textures of the different mushroom parts (e.g., stem, cap, lamellas),
potential discoloration, surrounding fauna, and others.
This meant that a visual, image-based classification task, while not entirely realistic, was at least possible
within the use case of mushroom hunting.
Once we had fixed mushroom hunting as our application scenario, it was time to design the first user
experiments.
Anatomy of a Study
Effects of Explainable Artificial Intelligence on trust and human behavior in a high-risk decision task
Benedikt Leichtmann, Christina Humer, Andreas Hinterreiter, Marc Streit, Martina Mara.
Computers in Human Behavior, 139: 107539, DOI: 10.1016/j.chb.2022.107539, 2023.
At this point, our still somewhat vaguely formulated research question was "How do explanations affect user trust
in a high-risk decision making task?".
The general idea was that we wanted to somehow vary the type of explanations that users received about an AI
prediction.
We planned to show them the output of an AI for a mushroom image (e.g., a predicted species based on an image
classification model) along with some sort of explanation.
We then wanted to ask the users to classify the mushroom themselves, either trusting the AI or overruling it.
Our idea was that different explanations should lead to different levels of user understanding, which in turn
should affect how often a user would trust the AI's prediction.
However, to answer our research question by means of a quantitative user study, we still needed to establish
several aspects in much more detail:
What exactly did we mean by explanations?
Should we choose a between- or within-subject design?
Which parameters did we want to manipulate?
How exactly should we implement the mushroom-picking task?
What were external factors that we need to consider?
Deciding on so many design parameters can be quite tricky.
Luckily, the psychologists in our team had plenty of experience with how to properly approach the design of user
studies.
Let Me Explain ...
As one of the first steps, we needed to fix what we meant by “explanation”.
Based on literature research, we assumed that two types of explanation could alter a user's understanding of an AI
decision.
First, the general principles and inner workings of the AI system can be explained to the user.
This way, a user should be able to better judge what a system, in general, is capable of and how trustworthy its
decisions are .
We called this type of explanation an “educational intervention”, so that our terminology would not
be too confusing.
Second, individual outcomes can be explained using XAI methods .
There are many different types of explanation techniques, and choosing any of them was a tough ask.
After lots of consideration, we opted for a combination of techniques.
This might not have been an ideal choice, but we'll get to that later.
Splitting (for) the Difference
Because it was unclear how these two different approaches, an educational intervention and individual explanations
of results, would compare to each other, we decided to go with a 2 × 2 between-subjects design
based on the two approaches.
Essentially, this meant that we would first split all our participants into two groups. We would give the
educational intervention to one group (i.e., they got some basic info on how our AI worked in general), while the
other group would not get anything at all.
Then, we would split each of the two groups again, with one half of each group getting individual explanations of
the AI predictions, and the other half only getting the AI predictions without explanations.
This resulted in four configurations: no extra information at all, educational intervention only, individual
explanations only, and both types of extra information.
While this meant that we had settled on our overall study design, it also meant that we could not vary any other
parameters.
Varying anything else would lead to a further subdivision of groups, requiring even more participants to obtain
reliable results.
We had known from the start that we wanted to present users with predictions from an actual mushroom
classification model, and not just with some fake outputs.
Now it was up to the ML-focused members of our group to train such a model and decide on all its different
parameters.
In the end, we opted for a ResNet 50 model pretrained on ImageNet data and
fine-tuned on several thousand mushroom
images that we collected from various sources (including the Danish Svampeatlas).
We also ensured that our model was bad enough to get some classifications wrong, as we wanted wrong AI
predictions to be reflected in the study.
Our study design with the 2 × 2 split based on the types of explanatory information also meant
that we only got to test one version for each of the two.
We had to fix one design for our educational intervention, and we had to fix one design for our XAI interface.
We use the term “interface” here for a reason.
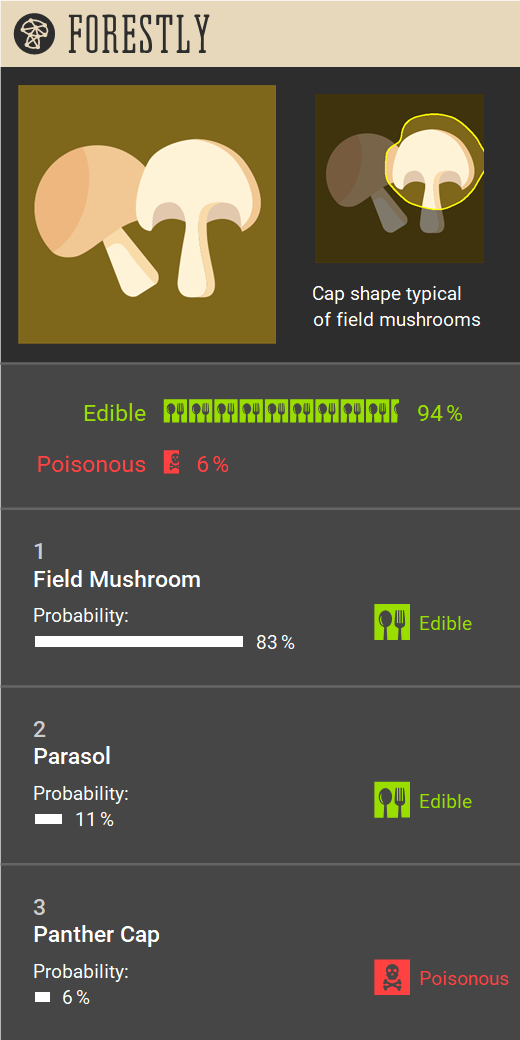
We decided that we wanted to show the results of our AI to the participants in the form of a fictitious mobile app
called Forestly.
This way, we tried to make the task of a joint human–AI mushroom classification in our experiment resemble
that of a real-world scenario of going out into the forest with an app.
Educational intervention designed for the first study (click to expand).
Above you can see the educational intervention that we used in the study (click on it to
expand it).
Below are the two variants of the Forestly app, one with and one without XAI content.
Hover over the boxes to receive extra info on the components of the Forestly app.
Participants in the study also received this information but in a static form.
The Forestly interface used in the first study. Hover over the interface elements or the descriptions
to reveal connecting lines.
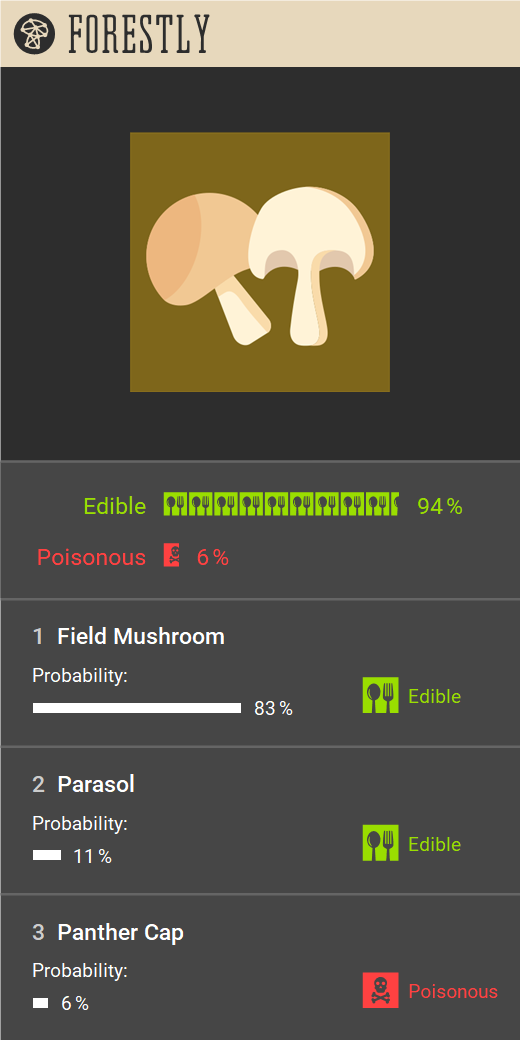
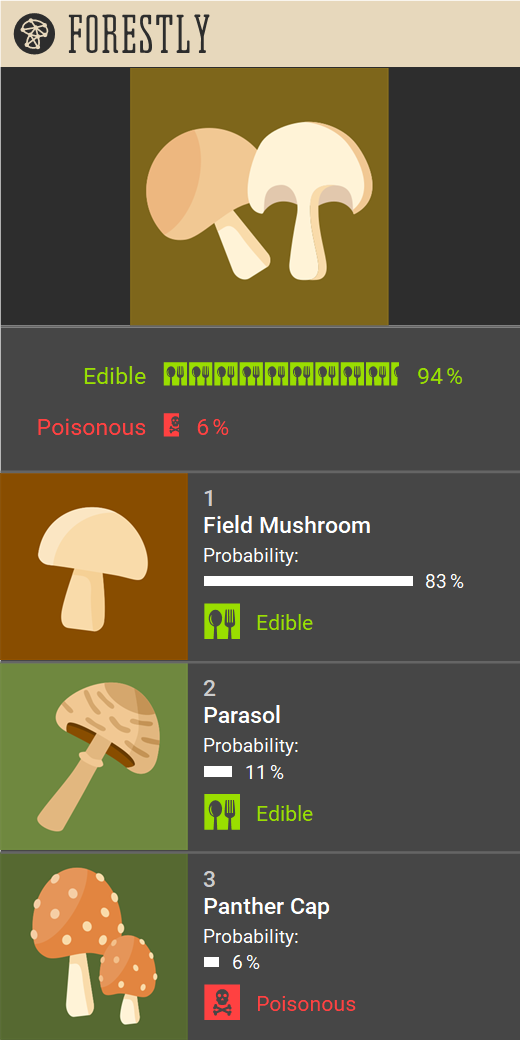
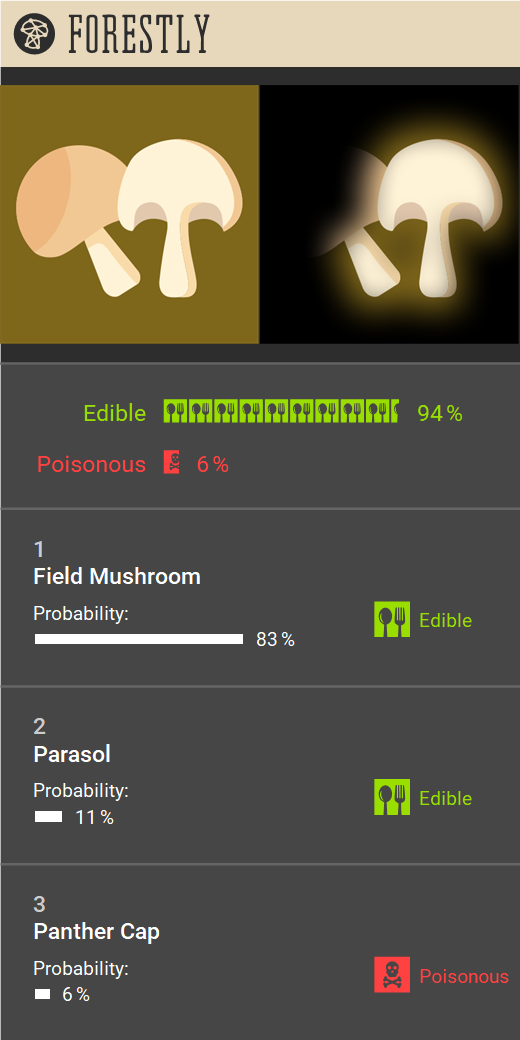
As you can see, we decided that both Forestly interfaces should show a ranking of predicted species.
For each predicted species, the interface shows percentages of likelihood (obtained through dropout during
inference), and the ground truth edibility.
We also added an aggregated edibility score based on these predictions in both variants.
For the explanations, we opted for a combination of nearest neighbors and Grad-CAM .
The nearest-neighbor explanation shows the nearest neighbor of the input image in the latent space of the
model for each predicted species (similar to an approach used previously by Jeyakumar et al. ).
The Grad-CAM explanation highlights the regions of the image that were important for the classification.
Tried and Tested
We had decided early on in our project that we were targeting a broad and diverse range of study participants.
This meant that we could not expect any prior knowledge, neither about mushrooms nor about AI.
To understand if the effects of explanations vary with different levels of prior knowledge about either topic, we
constructed pretests.
The first pretest collected information about the participants' mushroom knowledge.
We created it in cooperation with mycologists from Austria and Germany.
The second pretest aimed at the participants' knowledge about AI.
We created this one based on our own intuition and experience with communicating the topic to different audiences.
We also created a third test for what we called “task-specific AI comprehension”.
This test, which was scheduled at the end of the study, asked questions about applying AI to mushroom
identification.
In hindsight, this test was probably not necessary, as it strongly correlated with the AI test—you can see
that for yourself in a minute.
We had to make sure that each test included questions spanning from easy to very hard.
Only then could the tests fully cover the spectrum of knowledge levels in our broad participant population.
We pretested the pretests with friends, colleagues, and relatives to make sure that this was the case.
Stimulating!
Finally, we had to decide on the actual tasks and stimuli.
Stimuli are the items that participants see during the study which prompt them to perform a certain task.
Earlier on, we mentioned that it makes sense for a user to trust the AI if its prediction is correct and distrust
incorrect predictions.
Even though a user cannot know which is the case, we still wanted correct and incorrect AI predictions to be
reflected among our items.
Additionally, we thought it could make a big difference whether certain mushroom species were well known, and
whether the AI's aggregated prediction was “edible” or “poisonous”.
In a laborious process, we browsed through hundreds of input images, predictions, and explanations, attempting to
choose the ideal subset of stimuli.
To increase the potential risk of incorrect classifications, we limited ourselves to mushroom species that had
known doppelgangers.
You can see the images that we chose (for now, without any AI predictions) in the gallery below.
We told our participants to imagine going out into the forest to collect mushrooms for a nice stew with the help
of the Forestly app.
We showed the mushroom images and the AI predictions in the form of the Forestly interface to the
participants and asked them two questions for each item:
Would you classify this mushroom as edible or inedible/poisonous?
Would you pick up this mushroom and use it for cooking?
We split the question into two parts because we thought that it would be interesting to see if participants were
more conservative in their choices when it came to actually picking the mushroom versus superficially gauging its
edibility.
After each item, we also asked participants how much they trusted the app.
After both pretests and the actual mushroom classification, we concluded the experiment with the
“task-specific AI comprehension” test and general questions about the participants' intention to use
the Forestly app or similar systems.
Crunching the Numbers
We recruited 410 participants for this first experiment, which was carried out as an online study.
This number was based on an a priori power analysis.
We also performed a quantitative analysis of the results based on all the best practices established by
psychologists.
These are quite a bit more rigorous than what you would usually see in a visualization or ML paper with user
studies.
The interactive plotting tool below lets you explore different aspects of our results.
The main result was that additional explanations (the XAI kind) help users to make statistically significantly
more correct decisions, while the education intervention had no significant effect.
All the detailed results can be found in the paper.
Explore the Data from the First Study
The widget to the right lets you plot different attributes of our dataset collected from the first study.
You can select attributes for the x-axis and the y-axis. For categorical attributes on the
x-axis, means and standard deviations are shown for y. For numerical attributes on both axes,
2D histograms are shown. Here are some suggestions (click on the links to automatically jump to these
settings):
Can you find some other interesting relationships?
Going Artistic
Explainable Artificial Intelligence improves human decision-making: Results from a mushroom picking experiment
at a public art festival
Benedikt Leichtmann, Andreas Hinterreiter, Christina Humer, Marc Streit, Martina Mara.
International Journal of Human–Computer Interaction, DOI: 10.1080/10447318.2023.2221605, 2023.
Every year, the city of Linz in Austria is home to the Ars
Electronica Festival—a festival for art, technology, and society.
For several years, the campus of our university (Johannes Kepler University
Linz) was one of the main sites of the festival.
In those years, university members could apply for an exhibition site to showcase artistic aspects of their
research projects.
In the 2021 edition, we used this opportunity to be
present with our research project.
We created a concept for an installation called AI Forest that would serve as a hybrid between an
artistic narrative space and a research environment.
Our goal was to check if we could reproduce results from the first study with festival visitors in an engaging
setting.
To this end, we came up with two extensions to our first study:
We wanted to use gamification to make the mushroom classification task more exciting and motivating.
We wanted visitors to feel closer to an actual mushroom hunting trip to the forest.
I Want to Play a Game
For the first part—the gamification—we decided to embed the survey from the first study in a game
optimized for
tablet computers.
The story of the game was similar to our motivating scenario mentioned earlier: the game was about a mushroom hunt
with the intention of collecting enough mushrooms for a nice stew.
Obviously, only edible mushrooms should be collected.
After shortened versions of our pretests, visitors of our installation would search for physical mushroom models
in the AI Forest.
They would scan QR codes on these models to be presented with the classification tasks from the study on the
tablet.
Here, we used the same two versions of Forestly as previously.
We got rid of the education intervention because it did not work in our first study.
As stimuli, we used the subset of 10 mushrooms that had the most variance in the pilot study.
Through the shortened pretests and the fewer classification items, we could cut down the completion time of the
survey.
This was necessary because festival visitors naturally could not spend too much time at our installation, and the
newly introduced task of searching for the mushrooms would also take some time.
After completing the game (i.e., finding and scanning 10 mushrooms), visitors would get feedback on their result.
Below you can see the different outcomes of the game.
Success! The player collected all the edible mushrooms and no poisonous ones. The stew turned out
great!
Pretty good. The player collected some edible mushrooms and no poisonous ones. The stew turned out fine.
Oh no! The player collected at least one poisonous mushroom. Maybe it would be better to order some pizza
instead?
Hmm ... The player did not collect any mushrooms at all. The dinner guests will stay hungry.
Which of the end screens will you see?
Play the Game to find out
Shortened version of the mushroom hunting game originally implemented for the festival study.
While you were just presented with different mushroom items one after the other, our festival visitors had to
do a bit more work.
They actually had to find and scan mushroom models in an artificial forest environment.
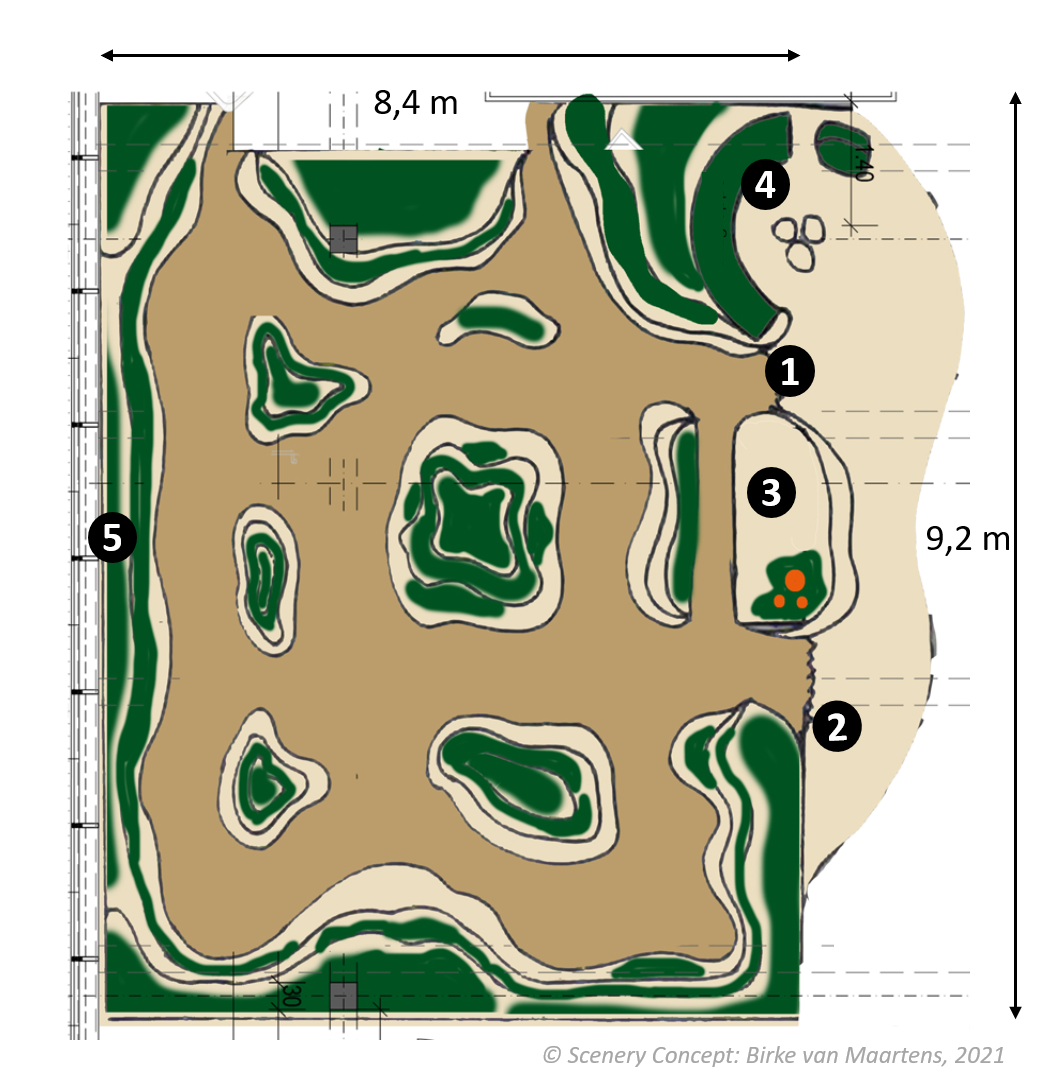
Wood Chips & Fragrance Dispensers
The AI Forest installation consisted of an artificial forest envisioned by German artist Birke van
Maartens.
A team of stage builders constructed it from various materials.
Pedestals made from wood and vinyl served as “islands” on which different plants were placed.
In total, we used 80 potted ivy and fern plants and around 30 large tree branches, which emulated trees.
Visitors, each holding a tablet computer with the game installed, walked between these islands on wood chips.
Hidden throughout the forest were not only mushroom models—which had QR codes printed on them so that
they could be scanned with the tablets—but also speakers and fragrance dispensers.
The speakers played bird songs from Austrian bird species, rustling wind noises, and one played the sounds of a
nearby stream of water.
These sounds were specially curated by audio artist Kenji Tanaka.
The fragrance dispensers released vapor smelling of fir, spruce, and different pine trees.
In the gallery below, you can get some impressions of what the whole installation looked like.
Throughout our three-day presence at the Ars Electronica Festival, we welcomed 466 visitors to our AI
Forest.
We could use the study data from 328 of these participants.
We did not use data from participants who played the game together (e.g., parents with their children), and some
visitors could not finish the entire game due to time constraints of their visit.
In addition to the study data, we also got a lot of feedback from informal conversations with people after their
visits.
With the new data from the festival, we could reproduce the main result from our first study.
Participants who got the XAI interface, again, performed better in terms of classification correctness than
participants who got the plain interface—and this effect was statistically significant again.
However, we could not reproduce some of our results regarding self-reported trust and rating of the app.
In our paper, you can find a detailed discussion of
these results and their implications .
In any case, our experiments show that replication studies are important to
understand which effects are reliable and generalizable.
What's the Difference?
Reassuring, Misleading, Debunking: Comparing Effects of XAI Methods on Human Decisions
Christina Humer, Andreas Hinterreiter, Benedikt Leichtmann, Martina Mara, Marc Streit.
OSF Preprint, DOI: 10.31219/osf.io/h6dwz, 2023.
After our first online study and the gamified replication study at the festival, we now had reliable results about
our XAI interface helping users to make more correct decisions (i.e., to trust the AI more adequately).
We mentioned earlier that when we designed our XAI interface, we opted for a
combination of nearest neighbors and Grad-CAM.
While we did know now that this combination worked, we did not know if that was because nearest neighbors worked,
Grad-CAM worked, or the combination worked.
We set out to perform a third study with new Forestly interfaces, in each of which only one
explanation technique was used.
This also gave us the opportunity to study an additional explanation technique.
A New Challenger Has Appeared
Based on informal feedback from the participants of our festival study, we got the feeling that most people had a
hard
time understanding and using Grad-CAM.
Most of the participants from the XAI group told us that they had looked mostly at the nearest-neighbor images.
We hoped to create a third explanation technique, which would improve upon Grad-CAM by not only showing an
attribution map but also relating the map to concepts tied to mushrooms.
For this new technique, we took inspiration from the network dissection technique .
We calculated the most important units of our neural network for each classification.
We then assigned semantic labels to the units and showed the activation maps of the units along with the labels.
With this new interface variant, we now had four Forestly variants: no explanations, nearest neighbors
(now without Grad-CAM), Grad-CAM (now without nearest neighbors), and the new semantic explanations.
Control interface with no explanations
Forestly interface with nearest-neighbor explanations.
Forestly interface with Grad-CAM explanations.
Forestly interface with semantic explanations.
In our third study, we divided our participants into four groups. Each group received one of the four
layout variants shown above. But there was one more thing we wanted to explore in our study …
Something's Awry
Remember when we mentioned the painstaking process of selecting certain mushroom
images as stimuli? One thing we noticed while browsing through hundreds of mushroom classifications and
their explanations was that sometimes an explanation could be “reassuring“. It could make you think
“Well, looks like everything makes sense here.“ At other times, looking at an explanation could raise
some concerns and make you think “Hmm, something's not quite right here.“ For example, a Grad-CAM
explanation could highlight only strange regions in the background of the mushroom image. Would you trust an AI
prediction if the AI did not even focus on the mushroom itself?
Our rough understanding was that “reassuring“ explanations would be helpful if the AI was correct.
The other kind of explanation, which made things look a bit more shady, would be more helpful in cases when the
AI was incorrect. In these cases, you could then perhaps realize that something maybe wasn't quite right and
overrule the AI.
For our selection of mushroom stimuli, we classified the explanations into the two different types and made sure
to include some items of each kind.
We liked the gamification from the festival study, so we decided to reuse the game idea and update the game with
the new interfaces.
Like in the game version that you could play above, this time there was no scanning
of mushrooms—it was an online study after all.
The items appeared one after the other in a randomized order.
For this online experiment we recruited 501 participants.
Overall, the nearest-neighbor explanations were most helpful for improving the decision correctness.
Nearest neighbors and our new semantic explanations seemed to be particularly effective in the cases that we
hypothesized to be most “helpful” (i.e., reassuring explanations for correct AI predictions, and
concerning ones for incorrect predictions).
In addition to these statistically significant results, we present a number of exploratory analysis results in our preprint.
In the widget below, you can explore how participants performed in the pick-up task for different item subgroups.
Explore the Data from the Third Study
In the table on the right, each row lists one of the mushroom items from the study, with indications for
whether the AI prediction was correct () or incorrect (), whether the mushroom depicted was actually edible () or
poisonous (), and whether we deemed the explanation to be
reassuring (;
the explanation fits with AI prediction like two pieces of a puzzle) or to raise concerns ().
The two rightmost columns of the table show how many participants assumed the mushroom to be edible and how
many picked it up, respectively.
The chart in the top left of the widget shows the correctness of the pick-up decision faceted by
the four experimental groups and by the selection in the table. The average pick-up scores are indicated by
the dots and the standard deviations by the lines.
Clicking on the button in the head of a row facets the results by the value of that row. For example, if you
click “AI correctness”, one mark for each group will show the
correctness for only the mushroom items with an incorrect AI prediction, and one mark for the items with
correct AI predictions.
Hover over the image thumbnails to view the Forestly screens that the control group saw.
Hovering over XAI icons ( or
)
shows the screens for the respective variant.
In one of our game's end screens—the one for the case of at least one
poisonous mushroom picked up—the toxicity of the stew is apparent. In real life, unfortunately, a poisonous
stew does not emit green vapor and skull symbols. On the contrary, for many mushrooms you might not taste any
difference and only find out when it's too late. If you collected the mushrooms with AI assistance and ended up
poisoning one of your dinner guests, who would you blame?
This is exactly the question that interested us in a final study.
We had sneakily included the following scenario in the surveys of the festival and the second online study:
Assume you decide to take a mushroom with you based on a recommendation of the artificial intelligence and give
it to a friend to eat. It turns out that it was a poisonous mushroom, and your friend complains of nausea,
vomiting, and diarrhea.
We then asked the participants how much each agent in this scenario was to blame.
The different agents here are the participant themself, the AI, the AI's developers, and the poisoned friend.
In addition to the blaming questions, we also asked participants in one of the studies how they viewed
artificially intelligent agents in general.
We are currently looking into the results.
If you are interested in the relationship between blaming and concepts like mind perception, stay tuned for a
future publication.
Conclusions
Finally, we want to summarize some of our main insights from this multi-year, transdisciplinary research project.
Replication studies are important. Throughout the different studies, we tried to replicate several
findings. The festival study was a replication study of the first experiment in a different setting. The second
online study aimed at relating the effects observed for the combined interface to the individual explanation
techniques. In both cases, we found that certain effects could be replicated, while others might have been false
positives or tied to very specific study conditions. This allowed us to obtain reliable results.
We encourage all readers to consider replication studies for their own results as well as those of others.
The psychology research community has long accepted the importance of such replication studies.
We hope that the visualization community will continue its ongoing efforts into this direction .
There's much more to do. Designing user studies is difficult and comes with many, many choices.
A single study, or even a whole research project, can only focus on a few dependent and independent variables.
All others have to be left fixed as control variables.
In our experiments, this meant that we only used one specific model with a fixed accuracy.
However, the accuracy of the model (and if and how you communicate it to the user) might be an important mediating
factor for how much users trust an AI.
There are many more potential mediating factors.
There are also many more application scenarios apart from mushrooms.
It will be interesting to see how our results generalize in future studies.
It's fun to try new things. We started this project as a team consisting of computer scientists and
psychologists.
In the course of the project, we got to work with mycologists, graphic designers, visual and audio artists, and
stage builders.
Some of us also got to be guides for an art festival installation, talking to hundreds of visitors with all sorts
of personal backgrounds.
All of these interactions were incredibly rewarding and it was great fun to combine so many influences in a
research project.
There's hope. Our results strongly suggest that XAI can be one way to help users
towards a more responsible use of AI support systems.
Correctly designed explanations can lead users to trusting an AI more adequately.
As a result, we believe that XAI can and will play a big role in the future for trust calibration.
Remember the Erewhonians from the beginning of this article?
They chose to relinquish machines altogether because they saw too many risks.
But if people learn when to trust and when not to trust an AI, we will be able to keep artificially intelligent
systems as effective tools in our society.
Acknowledgments
This project would not have been possible without the support of many highly motivated people.
Huge thanks go to Nives Meloni, who was busy as a bee coordinating and managing the “AI Forest”
exhibition area.
We also want to express our veneration for everyone involved in the conceptualization and physical construction of
the forest: Birke van Maartens, who created the imaginative artistic concept and the scenery design; Leonie
Haasler and Gabriel Vitel for their diligent construction work; and Kenji Tanaka for the soothing sound design.
Another big shoutout goes to everyone involved in the game design: Stefan Eibelwimmer for his wonderful graphic
design work; Christopher Lindinger, who helped in the conceptualization of the game; and Moritz Heckmann for
implementing big chunks of the game's logic and animations.
We also thank all the student assistants and colleagues from the Robopsychology Lab at Johannes
Kepler University Linz for their great support during the festival—some even spontaneously stepped in as
exhibition guides when the number of visitors was high—as well as Alfio Ventura for helping out with various
things for the two online studies.
Additionally, we thank the Johannes Kepler University press team and Roman Peherstorfer and his team for the video
documentation of the installation.
Finally, we thank Otto Stoik and the members of the Mycological Working Group (MYAG) at the Biology Center
Linz, Austria, who supported us in the development of the mushroom knowledge test and provided mushroom
images for this study. We also thank the members of the German Mycological Society (DGfM) for providing additional
images.
Funding
The main part of this project work was funded by Johannes Kepler University Linz, Linz Institute of Technology
(LIT), the State of Upper Austria, and the Federal Ministry of Education, Science and Research under grant number
LIT-2019-7-SEE-117, awarded to Martina Mara and Marc Streit.
The “AI Forest” installation and tablet game could be realized by funding through the LIT Special Call
for the Ars Electronica Festival 2021 awarded to Martina Mara.
We gratefully acknowledge additional funding by the Austrian Science Fund under grant number FWF DFH 23--N, by
the State of Upper Austria through the Human-Interpretable Machine Learning project, and by the Johannes Kepler
Open Access Publishing Fund.